Use case 2
Building a (predictive) model
Diagram:
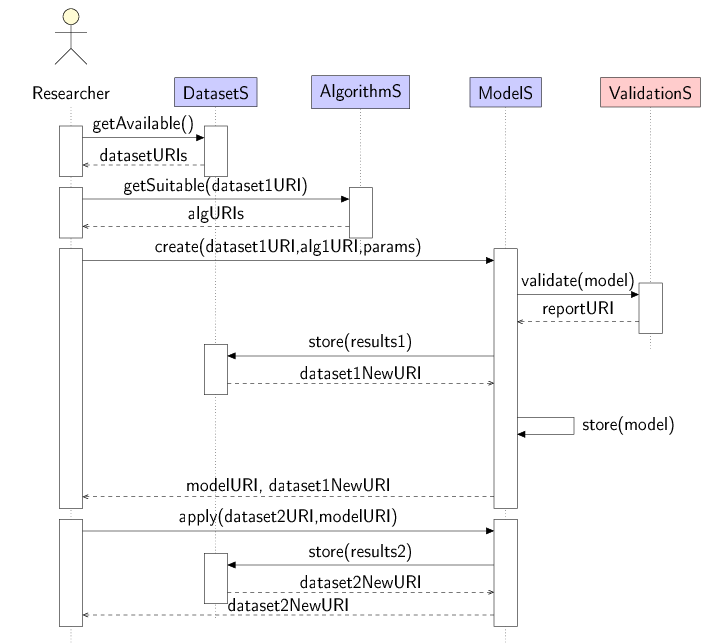
Name:
Building and using a prediction model
Brief Description:
A user applies an algorithm to a dataset and uses the resulting model on a different dataset. The results are stored as novel dataset within the system.
Actors:
A researcher with background in model building.
Basic Flow:
The user selects an algorithm and a dataset within the system to induce a model. The selection of the algorithm is based on the intended uses, i.e. within a supervised setting using a classification or regression algorithm. The algorithm possesses a number of default parameters, which can be adjusted to the users specifications. The user starts the induction process. Upon termination of the algorithm the user receives the result in form of a model. The user can supply an already existing second dataset and apply the model to it. The results are returned as novel dataset URI.
Preconditions:
- A dataset, identified by its URI, containing:
- One or more substance (URIs) each with
- a target feature (categorical/numerical)
- optionally additional numerical features (URI)
- One or more substance (URIs) each with
- An existing algorithm with default parameters for:
- Classification, requires
- a categorical target feature
- Regression, requires
- a numerical target feature
- Classification, requires
Postconditions:
Success End Condition:
- A model has been induced.
- If applicable, prediction on the second dataset have been produced and stored using this model.
Failure End Condition:
- No model has been induced.
- If applicable, no prediction on the second dataset could be produced and/or the results of applying the model to the second dataset could not be stored.
Minimal Guarantee:
- None
Relationship to other use cases:
When exchanging the actor Researcher to a validation algorithm, this use case could be part of a possible Validation use case.
Alternate Flows:
NA
Exception Flows:
Possible exceptions:
- Alternative 1: Only applicable algorithms can be selected:
- The dataset is empty/not accessible: the system returns an error code
- The supplied parameters are out of scope: the system returns an error code
- Alternative 2: User supplies dataset and algorithms without a selection process:
- As above, but extra:
- The supplied algorithm cannot be applied to the dataset: the system returns an error code
Extensions:
- Adopt model construction for Clustering
- Provide possibilities for feature construction
- Allow other types of features
Selecting a training data set:
- Include descriptor calculation services/APIs from SMILES (CDK), PDB files (crystallographic data, MOPAC), images (image analysis software).
- Preprocess (normalize or scale) of data.
- Include categorical features.
- Select subsets of the dataset (compounds and/or descriptors)
- Datasets are annotated with the the type of variables that they contain (numerical/categorical)