Data curation workflows using OpenRiskNet approach ready for demonstration
In the process of utilising the analysis tools available in the OpenRiskNet e-infrastructure, data needs to be accessed from different sources and various formats. Thus, the users should be able to access different data sources and specific entries. This are then being curated using an OpenRiskNet service and re-submitted to the data source.
Within DataCure case study, we aimed to establish a process for data curation and annotation that makes use of APIs and semantic annotations for a more systematic and reproducible data curation workflow. The development of semantic annotations and API definition for selected databases are also desired.
Therefore, the aim was to deliver curated and annotated datasets for OpenRiskNet service users as well as preparation of and development of tools that can allow users perform their own data curation.
To achieve these, OpenRiskNet developed resources that can make use of APIs as much as possible and eliminate the need for manual file sharing. In addition workflows that provide examples of useful data for toxicogenomic data analysis will be developed.
This case study serves also as the entry point of curation of data sources to be used by the other case studies.
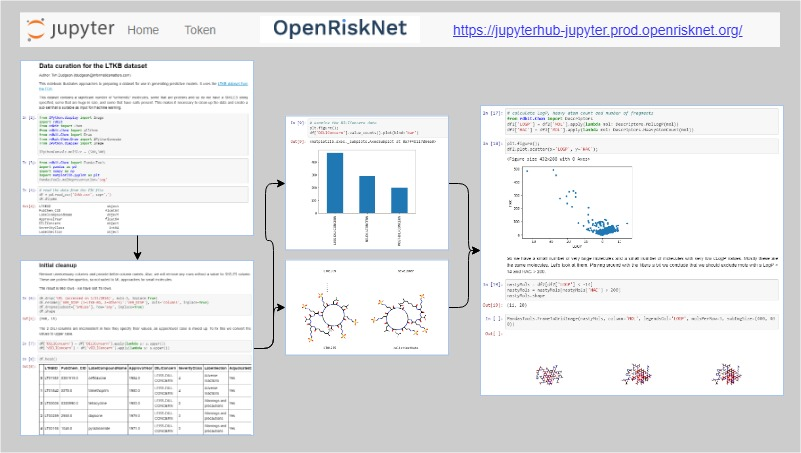
The technical implementation involved several steps related to the availability of data using EdelweissData Explorer as data source, the data extraction done by the use of API calls and text mining workflows, data searching using workflows that employ text mining capabilities, data curation and reasoning done through the provision of workflows stored in Jupyter notebooks, and finally re-submission to data source where the curated datasets may be re-submitted to the EdelweissData Explorer for re-usage.
To learn more on how this works in practice, you are invited to join a live demo session on 18 March 2019. Please see more details on the webinar and register here.